k8s学习笔记
控制器(3)
Job
Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
Spce格式
- spec.template格式同Pod
- RestartPolicy仅支持Never或OnFailure
- 单个Pod时,默认Pod成功运行后Job即结束
- .spec.completions标志Job结束需要成功运行的Pod个数,默认为1
- .spec.parallelism标志并行运行的Pod的个数,默认为1
- spec.activeDeadlineSeconds标志失败Pod的重试最大时间,超过这个时间不会继续重试
例子:
# job.yaml
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
template:
metadata:
name: pi
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
$ kubectl create -f ./job.yaml
job "pi" created
$ pods=$(kubectl get pods --selector=job-name=pi --output=jsonpath={.items..metadata.name})
$ kubectl logs $pods
3.141592653589793238462643383279502...
CronJob
Cron Job 管理基于时间的 Job,即:
- 在给定时间点只运行一次
- 周期性地在给定时间点运行
一个 CronJob 对象类似于 crontab (cron table)文件中的一行。它根据指定的预定计划周期性地运行一个 Job,格式可以参考 Cron 。
Spec
- .spec.schedule:调度,必需字段,指定任务运行周期,格式同 Cron
- .spec.jobTemplate:Job 模板,必需字段,指定需要运行的任务,格式同 Job
- .spec.startingDeadlineSeconds :启动 Job 的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的 Job 将被认为是失败的。如果没有指定,则没有期限
- .spec.concurrencyPolicy:并发策略,该字段也是可选的。它指定了如何处理被 Cron Job 创建的 Job 的并发执行。只允许指定下面策略中的一种:
-
Allow(默认):允许并发运行 Job -
Forbid:禁止并发运行,如果前一个还没有完成,则直接跳过下一个 -
Replace:取消当前正在运行的 Job,用一个新的来替换
注意,当前策略只能应用于同一个 Cron Job 创建的 Job。如果存在多个 Cron Job,它们创建的 Job 之间总是允许并发运行。
- .spec.suspend :挂起,该字段也是可选的。如果设置为 true,后续所有执行都会被挂起。它对已经开始执行的 Job 不起作用。默认值为 false。
- .spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit :历史限制,是可选的字段。它们指定了可以保留多少完成和失败的 Job。默认情况下,它们分别设置为 3 和 1。设置限制的值为 0,相关类型的 Job 完成后将不会被保留。
例子:
# test
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
$ kubectl create -f cronjob.yaml
cronjob "hello" created
kubectl run hello --schedule="*/1 * * * *" --restart=OnFailure --image=busybox -- /bin/sh -c "date; echo Hello from the Kubernetes cluster"
$ kubectl get cronjob
NAME SCHEDULE SUSPEND ACTIVE LAST-SCHEDULE
hello */1 * * * * False 0 <none>
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
hello-1202039034 1 1 49s
$ pods=$(kubectl get pods --selector=job-name=hello-1202039034 --output=jsonpath={.items..metadata.name})
$ kubectl logs $pods
Mon Aug 29 21:34:09 UTC 2016
Hello from the Kubernetes cluster
# 注意,删除 cronjob 的时候不会自动删除 job,这些 job 可以用 kubectl delete job 来删除
$ kubectl delete cronjob hello
cronjob "hello" deleted
限制
Cron Job 在每次调度运行时间内 大概 会创建一个 Job 对象。但是也有小概率可能创建多个Job。因此,创建 Job 操作应该是 幂等的。CronJob 根本就不会去检查 Pod, 而cronJob的创建的Job会根据它所创建的 Pod 的并行度,负责重试创建 Pod,并就决定这一组 Pod 的成功或失败。
删除
删除CronJob并不会删除由它创建的Job,只会中止正在创建的Job。需要用户手动清理:
$ kubectl get jobs
NAME DESIRED SUCCESSFUL AGE
hello-1201907962 1 1 11m
hello-1202039034 1 1 8m
...
$ kubectl delete jobs hello-1201907962 hello-1202039034 ...
job "hello-1201907962" deleted
job "hello-1202039034" deleted
...
# 删除namespace下所有的job
kubectl delete jobs --all
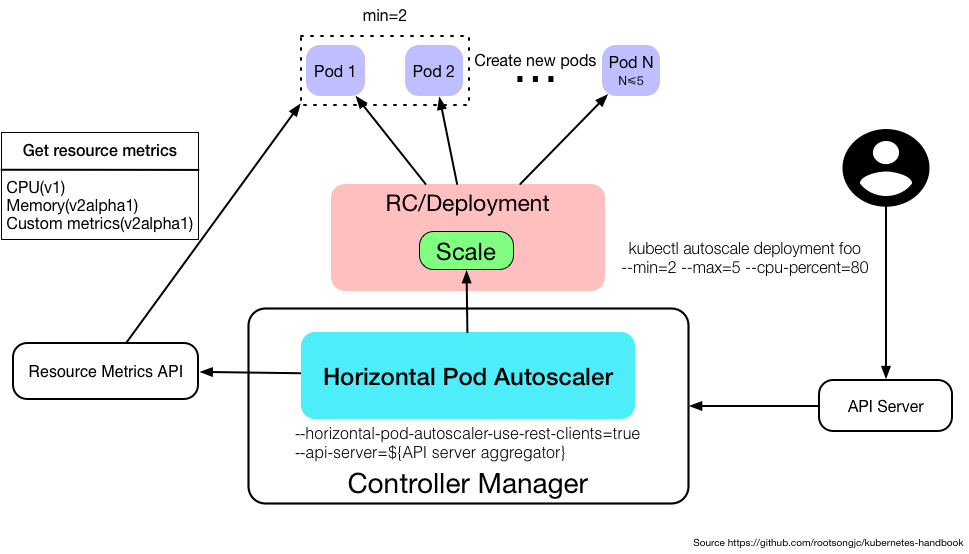
水平自动缩放(Horizontal Pod Autoscaling)
Horizontal Pod Autoscaling仅适用于Deployment和ReplicaSet和ReplicaController。可以根据CPU利用率内存使用以及哦嗯湖自定义的Metric扩容。
Metrics支持
- autoscaling/v1
- CPU
- autoscaling/v2beta2
- memory
- custom metrics
- multiple metrics
使用kubectl管理
Horizontal Pod Autoscaling作为API resource也可以像Pod、Deployment一样使用kubeclt命令管理,使用方法跟它们一样,资源名称为hpa。也可以通过kubectl autoscale直接通过命令行的方式创建Horizontal Pod Autoscaler。
例子:
kubectl create hpa
kubectl get hpa
kubectl describe hpa
kubectl delete hpa
kubectl autoscale deployment foo --min=2 --max=5 --cpu-percent=80
工作原理
Horizontal Pod Autoscaler 由一个控制循环实现,循环周期由 controller manager 中的 --horizontal-pod-autoscaler-sync-period 标志指定(默认是 30 秒)。在每个周期内,controller manager 会查询 HorizontalPodAutoscaler 中定义的 metric 的资源利用率。Controller manager 从 resource metric API(每个 pod 的 resource metric)或者自定义 metric API(所有的metric)中获取 metric。
自定义指标
Kubernetes中不仅支持CPU、内存为指标的HPA,还支持自定义指标的HPA,例如QPS。
配置
- 将kube-controller-manager的启动参数中–horizontal-pod-autoscaler-use-rest-clients设置为true,并指定–master为API server地址,如`–master=http://172.20.0.113:8080
- 修改kube-apiserver的配置文件apiserver,增加一条配置–requestheader-client-ca-file=/etc/kubernetes/ssl/ca.pem –requestheader-allowed-names=aggregator –requestheader-extra-headers-prefix=X-Remote-Extra- –requestheader-group-headers=X-Remote-Group –requestheader-username-headers=X-Remote-User –proxy-client-cert-file=/etc/kubernetes/ssl/kubernetes.pem –proxy-client-key-file=/etc/kubernetes/ssl/kubernetes-key.pem,用来配置aggregator的CA证书。
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1.custom-metrics.metrics.k8s.io
spec:
insecureSkipTLSVerify: true
group: custom-metrics.metrics.k8s.io
groupPriorityMinimum: 1000
versionPriority: 5
service:
name: api
namespace: custom-metrics
version: v1alpha1
- 部署Prometheus,
kubectl create prometheus-operator.yaml, prometheus
准入控制器
准入控制器(Admission Controller)位于 API Server 中,在对象被持久化之前,准入控制器拦截对 API Server 的请求,一般用来做身份验证和授权。通过API Server的启动参数配置。例如:
--admission-control=ServiceAccount,NamespaceLifecycle,NamespaceExists,LimitRanger,ResourceQuota,MutatingAdmissionWebhook,ValidatingAdmissionWebhook
adminission controller的种类参考